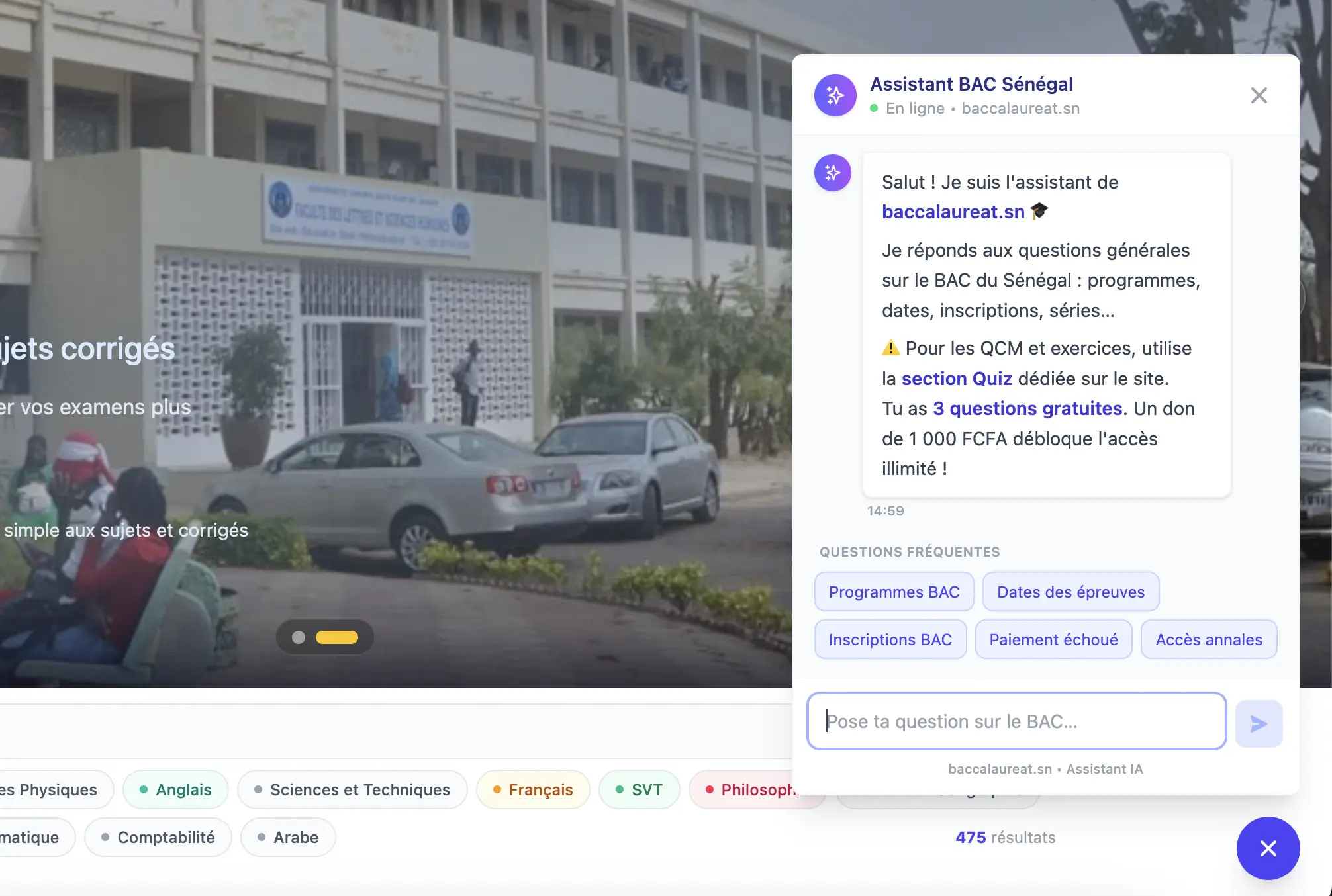
Le problème d'un chatbot « nu »
Brancher un LLM directement, c'est risquer des réponses génériques ou fausses (hallucinations). Sur baccalaureat.sn, l'assistant doit répondre à partir de MES contenus : annales, corrigés, fiches par matière et série. La solution : le RAG (Retrieval-Augmented Generation) — on récupère les passages pertinents de la base, puis on demande au LLM de répondre en s'appuyant dessus.
Le principe en trois temps
Question élève │ ▼ 1. RETRIEVAL : chercher les passages pertinents (annales, fiches) │ ▼ 2. AUGMENT : injecter ces passages dans le prompt comme contexte │ ▼ 3. GENERATION : le LLM répond EN S'APPUYANT sur le contexte fourni
Retrieval : commencer simple avec MySQL
Pas besoin d'une base vectorielle lourde pour démarrer. Un premier RAG efficace peut s'appuyer sur la recherche full-text MySQL, déjà en place.
final class AnnalesRetriever
{
public function search(string $query, int $limit = 4): array
{
$sql = <<connection->executeQuery($sql, [
'q' => $query, 'limit' => $limit,
], ['limit' => \PDO::PARAM_INT])->fetchAllAssociative();
}
}Le contenu est découpé en chunks (morceaux) indexés en full-text. On récupère les 4 plus pertinents pour la question.
Augment : construire le prompt
public function buildPrompt(string $question, array $chunks): array
{
$context = '';
foreach ($chunks as $c) {
$context .= sprintf(
"[%s - %s - %s]\n%s\n\n",
$c['matiere'], $c['serie'], $c['annee'], $c['contenu']
);
}
$system = << 'system', 'content' => $system],
['role' => 'system', 'content' => "CONTEXTE:\n{$context}"],
['role' => 'user', 'content' => $question],
];
}L'instruction « réponds UNIQUEMENT à partir du contexte » est la clé anti-hallucination : le LLM est cadré pour ne pas inventer.
Vers les embeddings quand ça grandit
Le full-text MySQL a ses limites : il matche des mots, pas du sens. « Comment calculer une dérivée » et « taux de variation instantané » sont proches sémantiquement mais ne partagent pas de mots-clés. L'étape suivante : indexer les chunks en embeddings (vecteurs de sens) et chercher par similarité cosinus.
// principe : chaque chunk a un vecteur ; on cherche les plus proches de la question $questionVec = $this->embedder->embed($question); $nearest = $this->vectorStore->search($questionVec, topK: 4);
Mais commencer en full-text permet de livrer vite et d'améliorer ensuite — la philosophie que j'applique sur tous mes projets.
Ce que je retiens
- RAG = récupérer d'abord, générer ensuite. On ancre le LLM sur SES données.
- Le full-text MySQL suffit pour un premier RAG utile, sans base vectorielle.
- L'instruction « uniquement à partir du contexte » réduit fortement les hallucinations.
- Découper le contenu en chunks bien dimensionnés est déterminant pour la qualité.
- Les embeddings viennent après, quand le besoin de recherche sémantique se fait sentir.